Yolov3 Explained – Yolov3 Paper
Di: Everly
概要 yolov3 において、損失の計算や推論結果の生成を行う yolo レイヤーの実装について解説します。 yolo レイヤー yolo レイヤーは yolov3 の出力層にあたる層で、特徴マップを入力とし
Simply talking, YOLO is an algorithm that uses convolutional neural networks for object detection. In comparison to recognition algorithms, a detection algorithm predicts class labels and detects objects‘ locations. In this tutorial, I
YOLOv3: An Incremental Improvement

In 2016 Redmon, Divvala, Girschick and Farhadi revolutionized object detection with a paper titled: You Only Look Once: Unified, Real-Time Object Detection. In the paper
In 2016 Redmon, Divvala, Girschick and Farhadi revolutionized object detection with a paper titled: You Only Look Once: Unified, Real-Time Object Detection. In the paper
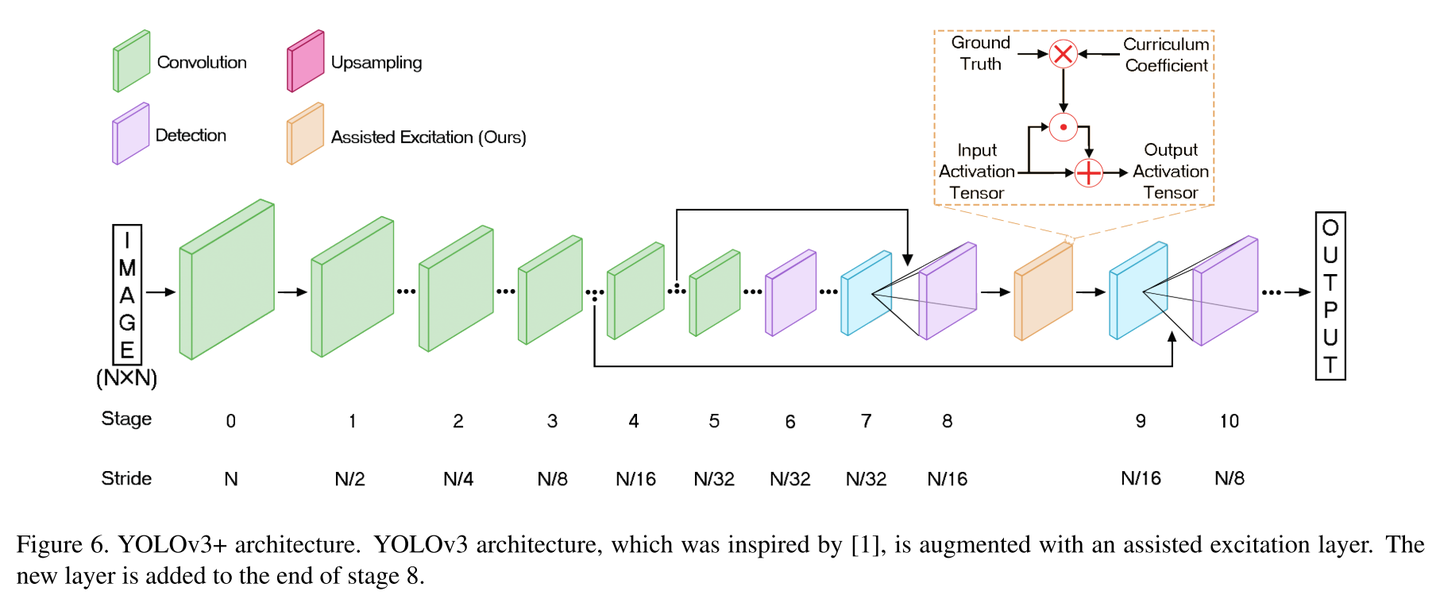
In this article, we have presented the Architecture of YOLOv3 model along with the changes in YOLOv3 compared to YOLOv1 and YOLOv2, how YOLOv3 maintains its accuracy and much
As explained in my previous post, each spatial cell in the network’s output layers predicts multiple boxes (3 in YOLO-V3, 5 in previous versions) — all centered in that cell, via a
- Getting Started with YOLO v3
- YOLO Explained: From v1 to Present
- The beginner’s guide to implementing Yolov3 in TensorFlow 2.0
YOLO v5 model architecture [Explained]
YOLOv3 is the latest variant of a popular object detection algorithm YOLO – You Only Look Once. The published model recognizes 80 different objects in images and videos, but most importantly, it is super fast and
It is a clever convolutional neural network (CNN) for object. detection used in real-time. Further, It is popular because it has a very high accuracy while also being able to run in
YOLOv3 is a real-time, single-stage object detection model that builds on YOLOv2 with several improvements. Improvements include the use of a new backbone network, Darknet-53 that utilises residual connections, or in the
However, the YOLO family continued to improve, we will look at YOLOv3. YOLOv3 Little Changes, Big Effects. A couple of years later, the researchers behind YOLO came up
YOLOv3 (You Only Look Once version 3) is a deep learning model architecture used for object detection in images and videos. It is a single neural network architecture that can detect objects in real-time with high
CSP-Darknet53 is just the convolutional network Darknet53 used as the backbone for YOLOv3 to which the authors applied the Cross Stage Partial (CSP) network strategy. Cross Stage Partial
物体検出モデル YOLOv3 の仕組みについて解説
3.4. Detection layers: YOLO has 3 detection layers that detect on 3 different scales using respective anchors. For each cell in the feature map, the detection layer predicts
YOLOv3 uses the DarkNet-53 as a backbone for feature extraction. The architecture has alternative 1×1 and 3×3 convolution layers and skip/residual connections inspired by the ResNet model. They also added the
In this project, I tried to establish a decent understanding from YOLO to see how the model works and the key that made it successful.To distinguish this project from others I have also
How YOLOv3 works? The YOLOv3 network divides an input image into S x S grid of cells and predicts bounding boxes as well as class probabilities for each grid.
In this blog, I’ll explain the architecture of YOLOv3 model, with its different layers, and see some results for object detection that I got while running the inference program on
YOLOv3 introduced a new backbone network, Darknet-53, which utilized residual connections. It also made several design changes to improve accuracy while maintaining speed. At 320×320
由于Yolov3采用了多尺度检测, 那么再检测时会有重复检测现象. 比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与
YOLO v3 Explained. How YOLOv3 works, from capturing the
YOLOv3 uses a few tricks to improve training and increase performance, including: multi-scale predictions, a better backbone classifier, and more. The full details are in our paper! Detection
In 2016 Redmon, Divvala, Girschick and Farhadi revolutionized object detection with a paper titled: You Only Look Once: Unified, Real-Time Object Detection. In the paper
As explained in my previous post, each spatial cell in the network’s output layers predicts multiple boxes (3 in YOLO-V3, 5 in previous versions) — all centered in that cell, via a
YOLOv3: An Incremental Improvement – arXiv.org
Introduction to YOLOv3. Following the YOLOv2 paper, In 2018, Joseph Redmon (a Graduate Student at the University of Washington) and Ali Farhadi (an Associate Professor at
YOLOv3 theory explained In this tutorial, I will explain to you what is YOLO v3 object detection model, and how it works behind the math
For the neck, they used the modified version of spatial pyramid pooling (SPP) from YOLOv3-spp and multi-scale predictions as in YOLOv3, but with a modified version of path aggregation
Output Layer Explanation: As you all know, YOLOv3 predicts bounding boxes in three different scales. In this section, we’ll understand the output layer of this network. Below I have attached an image of output layer
As explained in my previous post, each spatial cell in the network’s output layers predicts multiple boxes (3 in YOLO-V3, 5 in previous versions) — all centered in that cell, via a
YOLOv3 is a real-time object detection algorithm capable of detecting specific objects in videos and images. Leveraging features acquired through a deep convolutional neural network, the YOLO machine learning
YOLOv3 (You Only Look Once, Version 3) is a real-time object detection algorithm that identifies specific objects in videos, live feeds, or images. The YOLO machine learning
In 2016 Redmon, Divvala, Girschick and Farhadi revolutionized object detection with a paper titled: You Only Look Once: Unified, Real-Time Object Detection. In the paper
YOLOv3 has 2 important files: yolov3.cfg and yolov3.weights. The file yolov3.cfg contains all information related to the YOLOv3 architecture and its parameters, whereas the file
- Ikea: Zweite Chance _ Ikea Restposten Lager
- How To Cook Banquet Chicken Pot Pie In An Air Fryer
- Jugenduntersuchung | Jugenduntersuchung Ab Welchem Alter
- Eis Blumenball 2024
- Braunschweig-Veltenhof, 38112 Sandhofenstr. 2
- Solved: How To Create Variance Field And Variance %
- Vgb Klartext: Vgbahn Verlag Katalog
- Offenes Haus St Gallen: Frongartenstrasse 11 St Gallen
- Poweredge T20 Parts – Dell T20 Treiber Download
- Einfamilienhaus Kaufen In Blankenhagen, Blankenhagen
- How To Become A Veterinarian In Australia: A Complete Guide
- Börsenbrief Für Trendaktien: Börsenbrief Bernecker Kostenlos
- The Myths Of Origin Of The Indian Untouchables
- Sauna-Aufguss-Steine Saunazubehör
- The Cerebellum: Function, Location,