Trainieren Von Machine Learning-Modellen Mit Apache Spark
Di: Everly
Apache Spark stellt mit Spark MLlib eine Bibliothek spark.ml für verteiltes Machine Learning bereit. Sie beruht auf DataFrames und enthält neben Lernverfahren auch Methoden für die

Data Integration durch Databricks
Hier erfahren Sie, wie Sie die PREDICT-Funktion in serverlosen Apache Spark-Pools in Azure Synapse Analytics verwenden, um Bewertungen vorherzusagen. Sie können
Der dreitägige Apache Spark-Workshop ist ein intensiver Kurs, der den Teilnehmenden eine umfassende Einführung in die Verarbeitung großer Datenmengen mit Apache Spark und die
Trainieren eines Machine Learning-Modells mit word2vec und logistischer Regression und Verfolgen von Experimenten mit MLflow und der Fabric-Autologging-Funktion ;
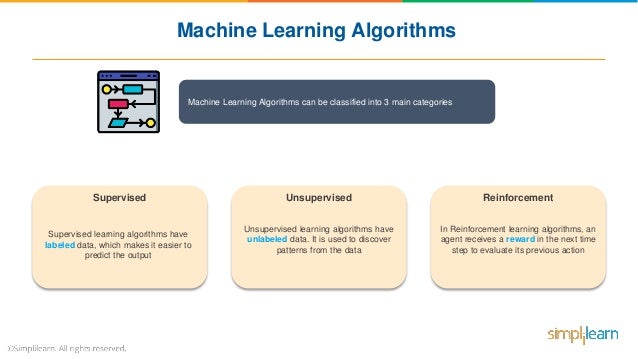
Maschinelle Lernalgorithmen und -bibliotheken können dabei helfen, Machine Learning-Modelle zu trainieren. Bibliotheksverwaltungstools können diese Bibliotheken und
In diesem Tutorial erfahren Sie, wie Sie Apache Spark MLlib verwenden, um eine Machine Learning-App zu erstellen, die ein Dataset mittels Klassifizierung durch logistische
- Machine Learning mit Apache Spark 2
- Trainieren von Explainable Boosting Machines
- Trainieren von Machine Learning-Modellen mit Apache Spark
Nach Abschluss des Trainings des Machine Learning-Modells können Sie die Leistung von trainierten Modellen auf zwei Arten bewerten. Öffnen Sie das gespeicherte
Trainieren von Explainable Boosting Machines
Spark 3.4 introduced the predict_batch_udf API, which provides a simple interface for DL model inference. This API handles automatic conversion from Spark DataFrame
Apache Spark dient als bevorzugtes verteilte Back-End. Charakteristiken. Fokus auf die Erstellung von skalierbarer Machine-Learning-Algorithmen. Implementiert gängige
Erfahren Sie, wie Sie das pyspark.ml.connect-Modul verwenden, um verteiltes maschinelles Lernen durchzuführen, um Spark ML-Modelle zu trainieren und den
Informationen zum Trainieren von Modellen mit SynapseML. Weiter zum Hauptinhalt. Dieser Browser wird nicht mehr unterstützt. Führen Sie ein Upgrade auf Microsoft Edge durch, um die
Verwenden Sie scikit-learn, LightGBM und MLflow, um Machine Learning-Modelle zu trainieren, und verwenden Sie die Fabric Autologging-Funktion zum Nachverfolgen von
Azure Databricks ist eine Plattform im Cloudmaßstab für Datenanalyse und Machine Learning. Data Scientists und Machine Learning-Engineers können Azure Databricks verwenden, um
Der erste Artikel behandelt den Aufbau und die Funktionsweise von Apache Spark, und der zweite Artikel zeigt anhand eines konkreten Beispiels die Entwicklung eines kompletten
Machine Learning mit Apache Spark
- Welche sind die besten Frameworks für KI und Machine Learning?
- SynapseML und seine Verwendung in Azure Synapse Analytics.
- Trainieren von Spark ML-Modellen in Databricks Connect mit
- Trainieren von Modellen mit SynapseML
Ich kann loslegen und meinen ersten eigenen Modelle trainieren ohne der TensorFlow oder Apache Spark Experte zu sein. Für erfahrene Benutzer wird beides auch
Beim Trainieren von Machine Learning-Modellen mithilfe von Azure Spark in Azure Synapse Analytics gibt es mehrere Möglichkeiten: Apache Spark MLlib, Azure Machine
Typisches Vorgehen beim maschinellen Lernen (ML) [1]:34 Beispiel für ein statistisches Modell: Die Linie (rot) zeigt ein lineares Modell für einfach strukturierte Beispieldaten (blau). Siehe
Beim Trainieren von Machine Learning-Modellen mithilfe von Azure Spark in Azure Synapse Analytics gibt es mehrere Optionen: Apache Spark MLlib, Azure Machine Learning und
Data Scientists und Machine Learning-Engineers können Azure Databricks verwenden, um Machine-Learning-Lösungen im großen Stil zu implementieren. Inhalt. Erkunden von Azure
Die Erstellung von Machine-Learning-Modellen mit dem Amazon SageMaker läuft immer nach dem gleichen Schema in 3 Schritten ab. Schritt 1 – Beispieldaten generieren .
Integration von Machine-Learning-Tools • Viele KI-Datenbanken bieten Integrationsmöglichkeiten für gängige Machine-Learning-Frameworks wie TensorFlow,
Lerne, wie du mit Azure Databricks Machine Learning-Lösungen erfolgreich realisierst. Hole dir deine Weiterbildung. Ruf an: 0800 258 258 055.
Voraussetzungen. In diesem Lernpfad wird davon ausgegangen, dass Sie über Erfahrung im Umgang mit Python für die Untersuchung von Daten verfügen und damit vertraut sind,
Mit Apache Spark können Sie wertvolle Erkenntnisse aus großen Mengen strukturierter, unstrukturierter und sich schnell verändernder Daten gewinnen. Beim Trainieren
Erfahren Sie mehr über AWS Trainium, den Machine Learning (ML)-Beschleuniger der zweiten Generation, den AWS speziell für das Deep-Learning-Training von Modellen mit mehr als 100
Apache Spark™ 3.0 bietet eine Reihe einfacher APIs für ETL, maschinelles Lernen und das Illustrieren massiver Verarbeitungsprozesse von riesigen Datensätzen aus einer Vielzahl von
Wer Modelle für das maschinelle Lernen entwickeln, trainieren und nutzen will, findet Unterstützung bei Amazons SageMaker.
Der dreitägige Apache Spark-Workshop ist ein intensiver Kurs, der den Teilnehmenden eine umfassende Einführung in die Verarbeitung großer Datenmengen mit Apache Spark und die
Lernen Sie, wie man Klassifizierungsmodelle mit Explainable Boosting Machines trainiert. Weiter zum Hauptinhalt. Dieser Browser wird nicht mehr unterstützt. Führen Sie ein
Verwalten von Versionen innerhalb eines Machine Learning-Modells. Ein Machine Learning-Modell enthält eine Sammlung von Modellversionen, um Nachverfolgung und
Machine Learning Modell trainieren. In diesem Schritt werden wir unser erstes Modell trainieren und validieren wie gut unser Machine Learning Modell die Klassen von
- ¿Cuáles Son Los 5 Municipios Más Pobres Del Estado De Hidalgo?
- Probefahrt| Autohaus Hessengarage Gmbh
- Skoda Fabia 2.0 Motorschaden _ Skoda Fabia 2.0 116 Ps
- Handbuch Soziale Arbeit Von Hans-Uwe Otto
- Bloqueio Indevido De Conta Bancária: O Que Você Precisa Saber?
- Always Choose Kind Quotes – Being Kind To Others Quotes
- Epics Und User Stories Unterscheiden
- Codigos Mining Simulator 2 Roblox
- Leuchte Auf Borussia! Bvb-Fans Liefern Gänsehaut-Choreo
- Parker Buch Reihenfolge: Robert B Parker Bücher