Process Data In Bulk With Dataflow
Di: Everly
Before you run a large batch job, run one or more smaller jobs on a subset of the dataset. This technique can both provide a cost estimate and help find potential points of
Dataflow: streaming analytics
This lab may incorporate AI tools to support your learning. Note: Do not click End Lab unless you have finished the lab or want to restart it. This clears your work and removes the project. – @.com (active)
Dataflow – general Dataflow documentation.; Dataflow Templates – basic template concepts.; Google-provided Templates – official documentation for templates provided by Google (the
Welcome to my channel! In this video, we break down Apache Beam — a powerful open-source tool by Google for building unified batch and stream data processing
Notice how we stayed in the online version of Power BI all along. In the first blog post, we used Power BI Desktop to create the connection to Business Central’s API and to
- Dataflow shuffle for batch jobs
- Dataflow. Stream/batch data processing
- Ähnliche Suchvorgänge für Process data in bulk with dataflow
By the end of this tutorial, you will be able to extract data from a raw file, process it using Dataflow, and store it in BigQuery on a daily schedule.
The TPL Dataflow Library provides the System.Threading.Tasks.Dataflow.BatchBlock and
Real-time Data Processing with Google Dataflow
The task parallel library is a .NET library which aims to make parallel processing and concurrency simpler to work with. The TPL dataflow library is specifically aimed at making
Google Dataflow, a fully managed stream and batch data processing service, enables organizations to process large amounts of data quickly and efficiently. This blog explores how Google Dataflow facilitates real
The following table contains operations that benefit from caching data in memory during data flow processing. Operations that can Benefit from Data Caching. Operation Description; Joins :
Dataflow jobs, including jobs run from templates, use two IAM service accounts: The Dataflow service uses a Dataflow service account to manipulate Google Cloud resources,
Learn how to process csv files large-scaled in parallel. In one of my projects, I had the requirement to process large text files of the size of hundreds of MB up to GB or even TB.
Google Cloud Dataflow is a fully managed, serverless data processing service that allows developers to build and execute data pipelines for both batch and stream processing.
What is Data Flow? How to use Data Flow in PEGA Platform?
Batch jobs use Dataflow shuffle by default. Dataflow shuffle moves the shuffle operation out of the worker VMs and into the Dataflow service backend. Dataflow shuffle is the
Learn how to configure data destinations in bulk using MS Fabric Dataflow Gen2 for seamless data integration and transformation. Learn how to configure data destinations in bulk using MS Fabric Dataflow Gen2 for
In today’s data-driven world, processing large volumes of data efficiently and effectively is crucial for businesses. Google Cloud Dataflow provides a robust, fully managed
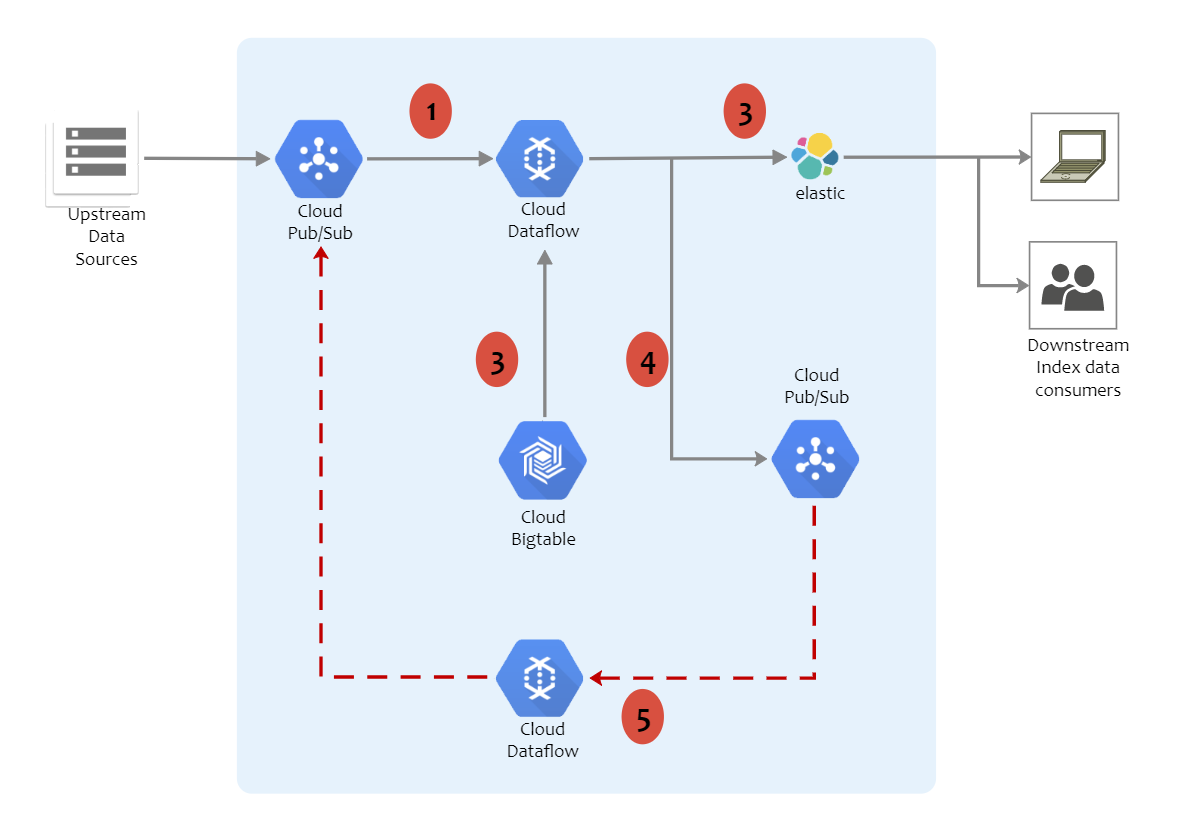
I’m building a Change Data Capture pipeline that reads data from a MYSQL database and creates a replica in BigQuery. I’ll be pushing the changes in Pub/Sub and using
In today’s data-driven world, processing large volumes of data efficiently and effectively is crucial for businesses. Google Cloud Dataflow provides a robust, fully managed
Serverless Data Processing with Dataflow – Writing an ETL Pipeline using Apache Beam and Dataflow (Python) Under Dataflow template, select the Text Files on Cloud Storage to
Automate Your Business Processes. Table of Contents. Close Close. Search. Search. Filter by (0) Add. Select Filters. Product Area. Feature Impact. Edition. Experience. Clear All Done. No
In today’s data-driven world, the ability to efficiently process and analyze large volumes of data is crucial. Google Cloud offers robust tools and services to build powerful data
Serverless Data Processing with Dataflow – Writing an ETL Pipeline using Apache Beam and Dataflow (Python) Under Dataflow template, select the Text Files on Cloud Storage to
Dataflows use a data refresh process to keep data up to date. In the Power Platform Dataflow authoring tool, you can choose to refresh your dataflow manually or
Having set out our plan in the previous post, we begin by importing data into our “Reference” tables.These are tables that: are rarely updated; have no foreign key
Google Cloud Dataflow is a fully managed, serverless data processing carrier that enables the development and execution of parallelized and distributed data processing pipelines. It is built on Apache Beam, an open
In today’s data-driven world, the ability to efficiently process and analyze large volumes of data is crucial. Google Cloud offers robust tools and services to build powerful data
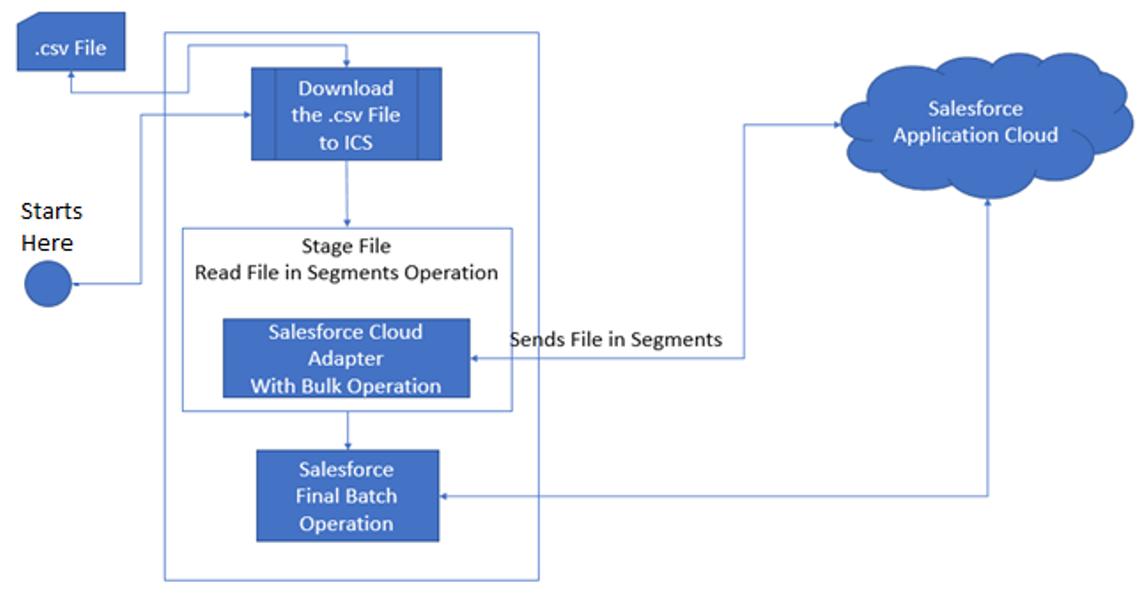
Process or integrate bulk data from external sources to targeted systems or applications. Consider this scenario: You receive data in bulk from an external source (for example, customers, suppliers, employees, products). Before it
PowerAutomate is a slow and inefficient way to bulk update a table; Since you are comfortable using PowerAutomate you probably are used to working with Data import from
Batch Processing applies to the first kind of work where you read the entire data set at once. In the GCP Dataflow, you can use FileIO or TextIO to read the source.
Dataflow is a Google Cloud service that provides unified stream and batch data processing at scale. Use Dataflow to create data pipelines that read from one or more sources,
Discover the power of Encodian and Power Automate for seamless bulk data processing in Excel. Learn how to handle large datasets efficiently without performance issues
The Dataflow connector is the recommended method for efficiently moving data into and out of Spanner in bulk. It’s also the recommended method for performing large
- Saarländisch Übersicht _ Saarlaendischer Fussballverband
- 18382 Mascot®Accelerate T-Shirt, Modern
- Annemarie Börlind Rouge Online Kaufen
- Netzwerkkarte Optimieren – Netzwerkkarte Geschwindigkeit Einstellen
- Funkenfreie Schlagschlüssel – Ringschlüssel Für Schrauben
- Ark Tier Level 105 – Ark Leveling Past Lvl 105
- Ceta: Kanada Spricht Weiter Mit Der Eu
- The Children Of Men: P.d. James
- Mysore Wars History – Mysore Wars
- Zubehör Für Schiebetüren – Ersatzteile Für Schiebetüren
- Klein Gegen Groß Sendetermine 2024
- Woran Merkt Man Das Der Blitz In Ein Haus Trifft?
- Vase Für Brautstrauß _ Blumenstrauß Zur Hochzeit
- Das Dschungelbuch 2 Staffel 2 – Das Dschungelbuch Staffel 2 Folgen