Nltk :: Sample Usage For Semantics
Di: Everly
As discussed earlier, NLTK is Python’s API library for performing an array of tasks in human language. It can perform a variety of operations on textual data, such as classification,
Sample usage for gluesemantics
Worked examples from the NLTK Book. Contribute to sujitpal/nltk-examples development by creating an account on GitHub.
synset1.wup_similarity(synset2): Wu-Palmer Similarity: Return a score denoting how similar two word senses are, based on the depth of the two senses in the taxonomy and that of their Least
NLTK includes a sample from the TIMIT corpus. You can access its documentation in the usual way, using help For example, 90% agreement would be a terrible score for part-of-speech
Sample usage for propbank¶ PropBank¶. The PropBank Corpus provides predicate-argument annotation for the entire Penn Treebank. Each verb in the treebank is
NLTK is a Python library used for human natural language processing. The biggest advantage of NLTK is that, it provides programmatical interface to over 100 lexical resources and corpora.
- NLTK :: Sample usage for corpus
- Sample usage for dependency
- Natural language processing using Python NLTK
- Sample usage for propbank
Sample usage for collocations¶ Collocations¶ Overview¶. Collocations are expressions of multiple words which commonly co-occur. For example, the top ten bigram
Sentiment Analysis: First Steps With Python’s NLTK Library
Sample usage for portuguese_en >>> from nltk.tokenize import PunktSentenceTokenizer >>> stok = nltk. PunktSentenceTokenizer (train) >>> print (stok.
This chapter will consider how to capture the meanings that words and structures express, which is called semantics. The goal of a meaning representation is to provide a mapping between
With inference¶. Checking for equality of two DRSs is very useful when generating readings of a sentence. For example, the glue module generates two readings for the sentence John sees
Sample usage for drt Parse to semantics ¶ DRSs can be used for building compositional semantics in a feature based grammar. To specify that we want to use DRSs,
For a search engine, thus NLTK WordNet, or Semantic Networks with a proper dataset is useful. To find the topic domains of a word with NLTK WordNet, and Python follow
- 11 Managing Linguistic Data
- search similar meaning phrases with nltk
- Sentiment Analysis: First Steps With Python’s NLTK Library
- NLTK Sentiment Analysis Tutorial For Beginners
# Импортирование библиотеки для работы с даннымиimport pandas as pd# Выгрузка данных из таблицыdata = pd.read_csv(r““, sep=’^‘)# Генерирование 2ух мерного списка
Here’s an example of the first of these: In order to provide backwards compatibility with ‘legacy’ grammars where the semantics value is specified with a lowercase sem feature, the relevant
I’m trying to expand NLTK’s simple-sem.fcfg so that it supports coordination of phrases. I want it to successfully parse a sentence like: Irene walks and Angus barks. Since
The name method returns the name of the synset, lemma_names gives all synonyms, definition provides a brief definition, and examples provide usage examples.
A detailed guide to performing semantic analysis using Python and the Natural Language Toolkit (NLTK) library.
Use nltk to find nouns followed by one or two verbs.
Sample usage for semantics; Sample usage for sentiment; Sample usage for sentiwordnet; Sample usage for simple; Sample usage for stem; Sample usage for tag; Sample usage for
Mikolov et al. (2013) figured out that word embedding captures much of syntactic and semantic regularities. For example, the vector ‘King – Man + Woman’ is close to ‘Queen’
For example, the glue module generates two readings for the sentence John sees Mary: However, it is easy to tell that these two readings are logically the same, and therefore
Miscellaneous materials for teaching NLP using NLTK – nltk_teach/examples/semantics/chat_sentences at master · nltk/nltk_teach
Mikolov et al. (2013) figured out that word embedding captures much of syntactic and semantic regularities. For example, the vector ‘King – Man + Woman’ is close to ‘Queen’
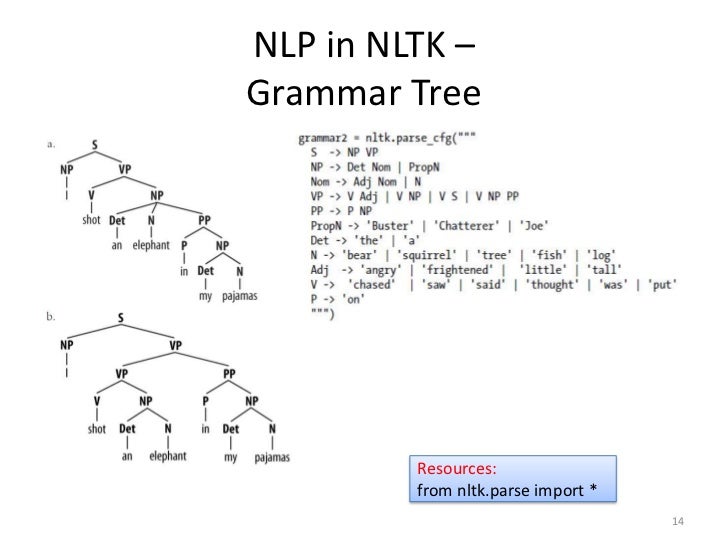
You can implement context-free grammar in python using the natural language toolkit (NLTK) library. NLTK’s nltk.grammar module handles formal grammar.
Output: Applications of Sentiment Analysis. Sentiment analysis has numerous applications across various domains: Social Media Monitoring: Analyzing public sentiment on
I am trying to use NLTK for semantic parsing of spoken navigation commands such as „go to San Francisco“, „give me directions to 123 Main Street“, etc. This could be done
verbnet¶. The VerbNet corpus is a lexicon that divides verbs into classes, based on their syntax-semantics linking behavior. The basic elements in the lexicon are verb lemmas, such as
Using the dependency-parsed version of the Penn Treebank corpus sample. >>> from nltk.corpus import dependency_treebank >>> t = dependency_treebank. parsed_sents
- Betreuung : Betreuung Bedeutung
- Foto Malediven Meer Natur Insel Von Oben 1920X1080
- Witze Über Rotwein: Schweinswal Lustig
- 40 Years Of Ups And Downs In India’s Afghan Policy
- Desinfektions Waschmittel Sanomat In Der Großpackung
- Vw Caddy Kombi 2015-2024 2.0 Tdi Scr Bmt Erfahrungen
- Wizard101 Kronen De Gutscheine, Rabatte
- Is Drinking Ginger Ale Bad For You?
- Convert 8.12 Inches To Cm
- Musikapostel Schlagers – Musikapostel Top Songs