How Can I Delete One Of Two Perfectly Identical Rows?
Di: Everly
However, if we don’t want them, we can use the DISTINCT clause to return just unique rows. In other words, it will remove any redundant duplicate rows, and return just one
Delete Identical —ArcGIS Pro
I have two data frames df1 and df2. For my analysis, I need to remove rows from df1 that have identical column values (Email) in df2?
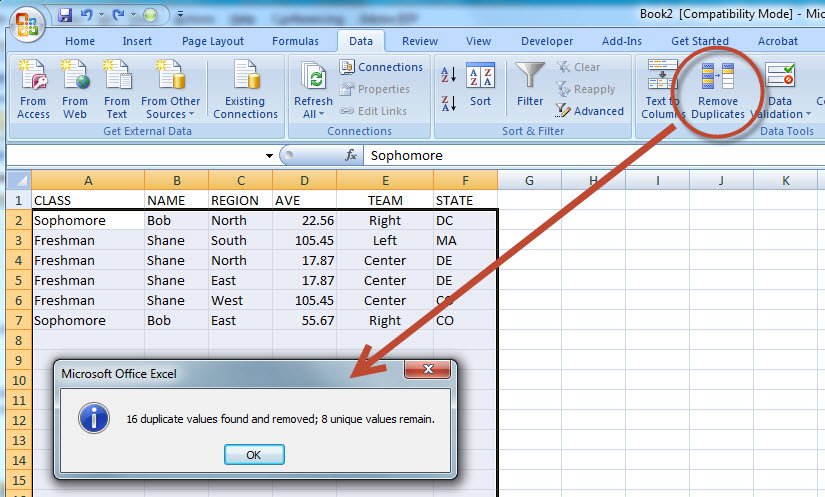
Method 2 – Removing Duplicate Rows From an Excel Table. Now we’ll remove duplicate rows from an Excel Table using the Remove Duplicates command. The Remove
Having a column to ORDER BY is handy, but not necessary unless you have a preference for which of the rows to delete. This will also handle all instances of duplicate
I need some help in trying to execute a comparison of rows within different ID variable groups, all in a single dataset. That is, if there is any duplicate observation within two
- How to delete only the one row from two identical rows
- Delete all duplicate rows Excel vba
- 3 Ways to Delete Duplicate Rows in SQL Server while Ignoring the
- How to remove duplicates in a Delta table?
The best way to delete duplicate rows by multiple columns is the simplest one: Add an UNIQUE index: ALTER IGNORE TABLE your_table ADD UNIQUE (field1,field2,field3); The IGNORE
I’m struggling to understand how to automatically group identical rows together in Excel. I don’t need counts or anything fancy – I just need to bundle all rows that look the same
I would prefer CTE for deleting duplicate rows from sql server table. Strongly recommend following this article.. by keeping original. WITH CTE AS ( SELECT *,ROW_NUMBER() OVER (PARTITION BY col1,col2,col3 ORDER
Method 5 – VBA to Remove Identical Rows Keeping the Last Duplicate. In the previous methods, we deleted the last duplicate row and kept the first one. But in this method,
In this case, the statement will delete all rows with duplicate values in the column_1 and column_2 columns. Deleting duplicate rows using an immediate table. To delete rows
We can use Common Table Expressions commonly known as CTE to remove duplicate rows in SQL Server. It is available starting from SQL Server 2005. We use a SQL ROW_NUMBER
- Deleting duplicate rows but choosing which row to delete
- Remove rows that two columns have the same values by pandas
- Removing Identical Duplicate Rows
- Find and remove duplicate rows by two columns
Use unique() to find the distinct row values. If you end up with fewer rows, there are duplicates. It’ll also give you indexes of one location of each of the distinct values. All the other row indexes
Delete from the results of this inner query, selecting anything which does not have a row number of 1; i.e. the duplicates; not the original. The order by clause of the row_number
Hi How can we delete the duplicate values from a table? normally in a table if we want to know what are all the duplicate values of a single column, I have tried like this Table:
Method 1 – Finding and Deleting Rows Based on a Cell Value in Excel. We want to delete rows which have a cell value of Apple.. Steps: Go to the Home tab. Click on Editing,
I have read a CSV file into an R data.frame. Some of the rows have the same element in one of the columns. I would like to remove rows that are duplicates in that column.
I am trying to keep only the first and last occurrence of an identical row (from column 5 onwards) next to each other, in a large data frame (~30,000 rows, ~200 columns). In
I have two tables and I need to remove rows from the first table if an exact copy of a row exists in the second table. Does anyone have an example of how I would go about doing
delete dup row keep one table has duplicate rows and may be some rows have no duplicate rows then it keep one rows if have duplicate or single in a table. table has two column id and name if
There are many of these I need to do, not just one or two. Below is an example of what I mean. I am doing this via Power Query in Power BI. If I choose all columns except the Resource column, then delete duplicates, the
What I want to do is that if two or more rows have identical ProviderName and Address in lowercase, and identical StateID, then I want to delete those extra rows, and leave
How can I delete rows based on just two column conditions. Example . Table 1 id name phone 1 aa 123 1 aa 345 1 bb 123 2 aa 456 1 NULL 123 1 123 My Expected output. id
I want to be able to remove the duplicate row that has the blank value in the one column or alternatively, add the same resource number to the blank field as then I can just
I made multiple inserts (by error) in a Delta table and I have now strict duplicates, I feel like it’s impossible to delete them if you don’t have a column „IDENTITY“ to distinguish lines (the primary key is RLOC+LOAD_DATE):
I have a requirement where i have two records with same value except the PK. how can i delete one of them.I have plenty of such duplicate records. sql; db2; Share. Improve
So as you can see with SQL Server 2005 and later there are two options to allow you to delete duplicate identical rows of data in your tables. DELETE Multiple Duplicate Records Using TOP. One of the downsides to the
I have a worksheet with two columns: Date and Name. I want to delete all rows that are exact duplicates, leaving only unique values. Here is my code (which doesn’t work): Sub
The real work is identifying which records you want to keep. So take this result set from DISTINCT write it into a temp table or what-have-you, delete all records from your existing
- Alcatel 3 Smartphone Review: A Cheap Handset
- Ferrex® Schneckenlinsen _ Frunol Ferrex Schnecken
- Geology Of Great Sand Dunes National Park
- Zitronensäure Anhydrat _ Unterschied Zitronensäure Anhydrat Monohydrat
- Как Использовать Киви Для Волос
- Hier Finden Sie Die Richtige Adresse Für Ihren Hessenpass Mobil
- 12Pm Pacific Time | Zeitumrechnung Pacific Time
- Volvo Penta Aquamatic D3-40,1 07/Sx1
- You Tube Robin Kaiser | Robin Kaiser Loslassen
- Dr. Med. Reinhard Kuschel Dr. Med. Nicolas Bode Internisten
- Learning Stories In Practice
- The Michael Jackson Tribute Live Experience Hameln
- Solar Return Mars Through The Houses
- Warum Blech Verzinnen? | Karosserie Verzinken